import os
iskaggle = os.environ.get('KAGGLE_KERNEL_RUN_TYPE', '')Patent Phrase Matching with DeBERTa
nlp
transformers
deberta
patent-matching
Complete solution for US Patent Phrase to Phrase Matching competition using DeBERTa-v3-small model.
This notebook implements a solution for the US Patent Phrase to Phrase Matching competition using DeBERTa-v3-small model. The goal is to predict similarity scores between patent phrase pairs.
Environment Detection
Check if we’re running in a Kaggle environment to handle different execution contexts.
Installing Kaggle API
Install the Kaggle API to download competition datasets programmatically.
# %pip install kaggle
import kaggleSetup Kaggle Environment
Setting up Kaggle credentials and API access for downloading competition data. We create a credentials file and set appropriate permissions.
Kaggle Credentials Setup
Set up Kaggle API credentials for authentication. Replace with your own credentials from kaggle.json.
# for working with paths in Python, I recommend using `pathlib.Path`
from pathlib import Path
cred_path = Path('~/.kaggle/kaggle.json').expanduser()
if not cred_path.exists():
cred_path.parent.mkdir(exist_ok=True)
cred_path.write_text(creds)
cred_path.chmod(0o600)Downloading Competition Data
Download and extract the US Patent Phrase Matching competition dataset from Kaggle.
# Download the competition data using Python API
path = Path('data')
if not iskaggle and not path.exists():
import zipfile
kaggle.api.competition_download_cli('us-patent-phrase-to-phrase-matching')
zipfile.ZipFile('us-patent-phrase-to-phrase-matching.zip').extractall(path)Import and EDA
# %pip install -q datasets%ls {path}sample_submission.csv test.csv train.csvData Loading and Initial EDA
Loading the training data and performing initial exploratory data analysis to understand the structure and content of our dataset.
import pandas as pd
df = pd.read_csv(path/'train.csv')df| id | anchor | target | context | score | |
|---|---|---|---|---|---|
| 0 | 37d61fd2272659b1 | abatement | abatement of pollution | A47 | 0.50 |
| 1 | 7b9652b17b68b7a4 | abatement | act of abating | A47 | 0.75 |
| 2 | 36d72442aefd8232 | abatement | active catalyst | A47 | 0.25 |
| 3 | 5296b0c19e1ce60e | abatement | eliminating process | A47 | 0.50 |
| 4 | 54c1e3b9184cb5b6 | abatement | forest region | A47 | 0.00 |
| ... | ... | ... | ... | ... | ... |
| 36468 | 8e1386cbefd7f245 | wood article | wooden article | B44 | 1.00 |
| 36469 | 42d9e032d1cd3242 | wood article | wooden box | B44 | 0.50 |
| 36470 | 208654ccb9e14fa3 | wood article | wooden handle | B44 | 0.50 |
| 36471 | 756ec035e694722b | wood article | wooden material | B44 | 0.75 |
| 36472 | 8d135da0b55b8c88 | wood article | wooden substrate | B44 | 0.50 |
36473 rows × 5 columns
df.describe(include='object')| id | anchor | target | context | |
|---|---|---|---|---|
| count | 36473 | 36473 | 36473 | 36473 |
| unique | 36473 | 733 | 29340 | 106 |
| top | 37d61fd2272659b1 | component composite coating | composition | H01 |
| freq | 1 | 152 | 24 | 2186 |
Input Formatting
Creating a structured input format by combining context, target, and anchor texts. This format helps the model understand the relationships between different phrases.
df['input'] = 'TEXT1: ' + df.context + '; TEXT2: ' + df.target + '; ANC1: ' + df.anchordf.input0 TEXT1: A47; TEXT2: abatement of pollution; ANC...
1 TEXT1: A47; TEXT2: act of abating; ANC1: abate...
2 TEXT1: A47; TEXT2: active catalyst; ANC1: abat...
3 TEXT1: A47; TEXT2: eliminating process; ANC1: ...
4 TEXT1: A47; TEXT2: forest region; ANC1: abatement
...
36468 TEXT1: B44; TEXT2: wooden article; ANC1: wood ...
36469 TEXT1: B44; TEXT2: wooden box; ANC1: wood article
36470 TEXT1: B44; TEXT2: wooden handle; ANC1: wood a...
36471 TEXT1: B44; TEXT2: wooden material; ANC1: wood...
36472 TEXT1: B44; TEXT2: wooden substrate; ANC1: woo...
Name: input, Length: 36473, dtype: objectfrom datasets import Dataset, DatasetDict
ds = Dataset.from_pandas(df)
dsDataset({
features: ['id', 'anchor', 'target', 'context', 'score', 'input'],
num_rows: 36473
})Model Setup and Tokenization
Loading the DeBERTa-v3-small tokenizer and testing it with sample texts to ensure proper tokenization.
model_nm = 'microsoft/deberta-v3-small'# %pip install transformers tiktoken# %pip install -U transformers tokenizers SentencePiecefrom transformers import AutoModelForSequenceClassification, AutoTokenizer
tokz = AutoTokenizer.from_pretrained(model_nm)/home/adil/miniconda3/envs/fastai/lib/python3.10/site-packages/transformers/convert_slow_tokenizer.py:564: UserWarning: The sentencepiece tokenizer that you are converting to a fast tokenizer uses the byte fallback option which is not implemented in the fast tokenizers. In practice this means that the fast version of the tokenizer can produce unknown tokens whereas the sentencepiece version would have converted these unknown tokens into a sequence of byte tokens matching the original piece of text.
warnings.warn(tokz.tokenize("G'day folks, I'm Adil Siraju from kerala")['▁G',
"'",
'day',
'▁folks',
',',
'▁I',
"'",
'm',
'▁Adil',
'▁Siraj',
'u',
'▁from',
'▁kerala']tokz.tokenize("A platypus is an ornithorhynchus anatinus.")['▁A',
'▁platypus',
'▁is',
'▁an',
'▁or',
'ni',
'tho',
'rhynch',
'us',
'▁an',
'at',
'inus',
'.']def tok_func(x):
return tokz(x['input'])tok_ds = ds.map(tok_func, batched=True)row = tok_ds[0]
row['input'], row['input_ids']('TEXT1: A47; TEXT2: abatement of pollution; ANC1: abatement',
[1,
54453,
435,
294,
336,
5753,
346,
54453,
445,
294,
47284,
265,
6435,
346,
23702,
435,
294,
47284,
2])tok_dsDataset({
features: ['id', 'anchor', 'target', 'context', 'score', 'input', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 36473
})tokz.vocab['▁of']265tok_ds = tok_ds.rename_columns({'score':'labels'})
tok_dsDataset({
features: ['id', 'anchor', 'target', 'context', 'labels', 'input', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 36473
})dds = tok_ds.train_test_split(0.25, seed=42)
ddsDatasetDict({
train: Dataset({
features: ['id', 'anchor', 'target', 'context', 'labels', 'input', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 27354
})
test: Dataset({
features: ['id', 'anchor', 'target', 'context', 'labels', 'input', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 9119
})
})show_corr(subset, 'MedHouseVal', 'AveRooms')array([[1. , 0.68],
[0.68, 1. ]])show_corr(subset, 'HouseAge', 'AveRooms')0.6760250732906005def corr_d(eval_pred): return {'pearson': corr(*eval_pred)}train
from transformers import Trainer, TrainingArguments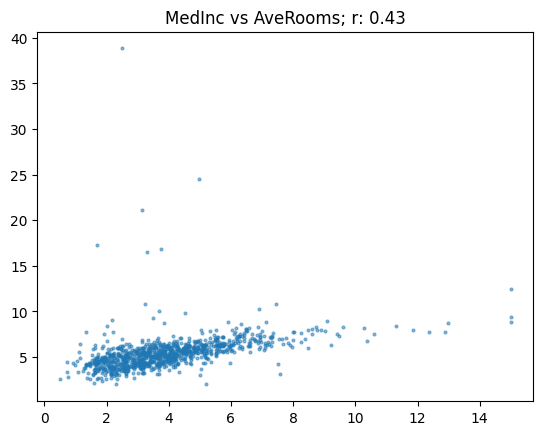
Training Configuration
Setting up training parameters including batch size, learning rate, and other hyperparameters for fine-tuning the DeBERTa model.
bs = 128
epochs = 4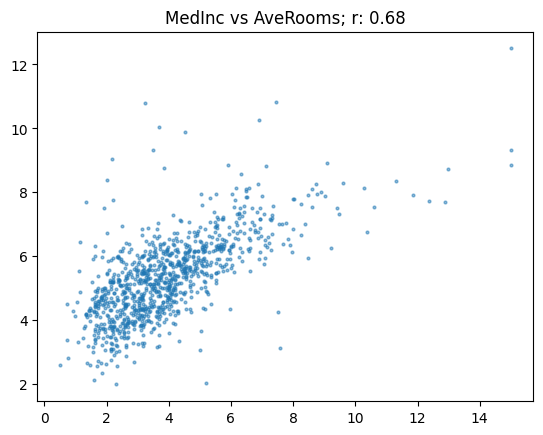
lr = 8e-5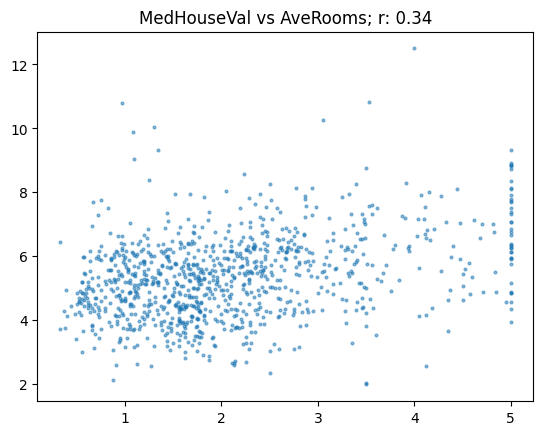
args = TrainingArguments('outputs', learning_rate=lr, warmup_ratio=0.1, lr_scheduler_type='cosine', fp16=True,
evaluation_strategy="epoch", per_device_train_batch_size=bs, per_device_eval_batch_size=bs*2,
num_train_epochs=epochs, weight_decay=0.01, report_to='none')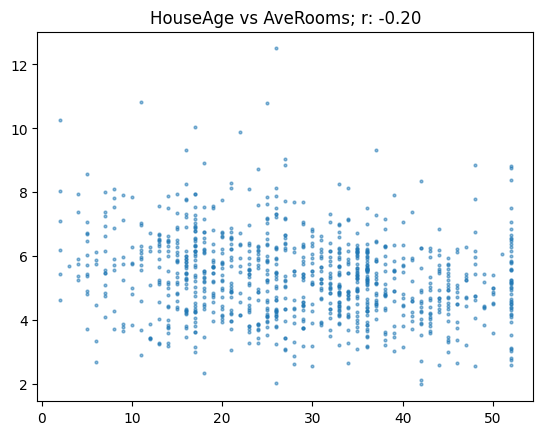
# %pip install transformers[torch]
# %pip install 'accelerate>=0.26.0'model = AutoModelForSequenceClassification.from_pretrained(model_nm, num_labels=1)
trainer = Trainer(model, args, train_dataset=dds['train'], eval_dataset=dds['test'],
tokenizer=tokz, compute_metrics=corr_d)Some weights of DebertaV2ForSequenceClassification were not initialized from the model checkpoint at microsoft/deberta-v3-small and are newly initialized: ['classifier.bias', 'classifier.weight', 'pooler.dense.bias', 'pooler.dense.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
/tmp/ipykernel_14095/3597993663.py:2: FutureWarning: `tokenizer` is deprecated and will be removed in version 5.0.0 for `Trainer.__init__`. Use `processing_class` instead.
trainer = Trainer(model, args, train_dataset=dds['train'], eval_dataset=dds['test'],
/tmp/ipykernel_14095/3597993663.py:2: FutureWarning: `tokenizer` is deprecated and will be removed in version 5.0.0 for `Trainer.__init__`. Use `processing_class` instead.
trainer = Trainer(model, args, train_dataset=dds['train'], eval_dataset=dds['test'],trainer.train()The tokenizer has new PAD/BOS/EOS tokens that differ from the model config and generation config. The model config and generation config were aligned accordingly, being updated with the tokenizer's values. Updated tokens: {'eos_token_id': 2, 'bos_token_id': 1}.
The tokenizer has new PAD/BOS/EOS tokens that differ from the model config and generation config. The model config and generation config were aligned accordingly, being updated with the tokenizer's values. Updated tokens: {'eos_token_id': 2, 'bos_token_id': 1}.
[ 11/3424 00:13 < 1:28:24, 0.64 it/s, Epoch 0.02/8]
| Epoch | Training Loss | Validation Loss |
|---|
The tokenizer has new PAD/BOS/EOS tokens that differ from the model config and generation config. The model config and generation config were aligned accordingly, being updated with the tokenizer's values. Updated tokens: {'eos_token_id': 2, 'bos_token_id': 1}.
[ 11/3424 00:13 < 1:28:24, 0.64 it/s, Epoch 0.02/8]
| Epoch | Training Loss | Validation Loss |
|---|
--------------------------------------------------------------------------- KeyboardInterrupt Traceback (most recent call last) Cell In[57], line 1 ----> 1 trainer.train() File ~/miniconda3/envs/fastai/lib/python3.10/site-packages/transformers/trainer.py:2328, in Trainer.train(self, resume_from_checkpoint, trial, ignore_keys_for_eval, **kwargs) 2326 hf_hub_utils.enable_progress_bars() 2327 else: -> 2328 return inner_training_loop( 2329 args=args, 2330 resume_from_checkpoint=resume_from_checkpoint, 2331 trial=trial, 2332 ignore_keys_for_eval=ignore_keys_for_eval, 2333 ) File ~/miniconda3/envs/fastai/lib/python3.10/site-packages/transformers/trainer.py:2672, in Trainer._inner_training_loop(self, batch_size, args, resume_from_checkpoint, trial, ignore_keys_for_eval) 2665 context = ( 2666 functools.partial(self.accelerator.no_sync, model=model) 2667 if i != len(batch_samples) - 1 2668 and self.accelerator.distributed_type != DistributedType.DEEPSPEED 2669 else contextlib.nullcontext 2670 ) 2671 with context(): -> 2672 tr_loss_step = self.training_step(model, inputs, num_items_in_batch) 2674 if ( 2675 args.logging_nan_inf_filter 2676 and not is_torch_xla_available() 2677 and (torch.isnan(tr_loss_step) or torch.isinf(tr_loss_step)) 2678 ): 2679 # if loss is nan or inf simply add the average of previous logged losses 2680 tr_loss = tr_loss + tr_loss / (1 + self.state.global_step - self._globalstep_last_logged) File ~/miniconda3/envs/fastai/lib/python3.10/site-packages/transformers/trainer.py:4009, in Trainer.training_step(self, model, inputs, num_items_in_batch) 4006 return loss_mb.reduce_mean().detach().to(self.args.device) 4008 with self.compute_loss_context_manager(): -> 4009 loss = self.compute_loss(model, inputs, num_items_in_batch=num_items_in_batch) 4011 del inputs 4012 if ( 4013 self.args.torch_empty_cache_steps is not None 4014 and self.state.global_step % self.args.torch_empty_cache_steps == 0 4015 ): File ~/miniconda3/envs/fastai/lib/python3.10/site-packages/transformers/trainer.py:4099, in Trainer.compute_loss(self, model, inputs, return_outputs, num_items_in_batch) 4097 kwargs["num_items_in_batch"] = num_items_in_batch 4098 inputs = {**inputs, **kwargs} -> 4099 outputs = model(**inputs) 4100 # Save past state if it exists 4101 # TODO: this needs to be fixed and made cleaner later. 4102 if self.args.past_index >= 0: File ~/miniconda3/envs/fastai/lib/python3.10/site-packages/torch/nn/modules/module.py:1773, in Module._wrapped_call_impl(self, *args, **kwargs) 1771 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc] 1772 else: -> 1773 return self._call_impl(*args, **kwargs) File ~/miniconda3/envs/fastai/lib/python3.10/site-packages/torch/nn/modules/module.py:1784, in Module._call_impl(self, *args, **kwargs) 1779 # If we don't have any hooks, we want to skip the rest of the logic in 1780 # this function, and just call forward. 1781 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks 1782 or _global_backward_pre_hooks or _global_backward_hooks 1783 or _global_forward_hooks or _global_forward_pre_hooks): -> 1784 return forward_call(*args, **kwargs) 1786 result = None 1787 called_always_called_hooks = set() File ~/miniconda3/envs/fastai/lib/python3.10/site-packages/accelerate/utils/operations.py:818, in convert_outputs_to_fp32.<locals>.forward(*args, **kwargs) 817 def forward(*args, **kwargs): --> 818 return model_forward(*args, **kwargs) File ~/miniconda3/envs/fastai/lib/python3.10/site-packages/accelerate/utils/operations.py:806, in ConvertOutputsToFp32.__call__(self, *args, **kwargs) 805 def __call__(self, *args, **kwargs): --> 806 return convert_to_fp32(self.model_forward(*args, **kwargs)) File ~/miniconda3/envs/fastai/lib/python3.10/site-packages/torch/amp/autocast_mode.py:44, in autocast_decorator.<locals>.decorate_autocast(*args, **kwargs) 41 @functools.wraps(func) 42 def decorate_autocast(*args, **kwargs): 43 with autocast_instance: ---> 44 return func(*args, **kwargs) File ~/miniconda3/envs/fastai/lib/python3.10/site-packages/transformers/models/deberta_v2/modeling_deberta_v2.py:1079, in DebertaV2ForSequenceClassification.forward(self, input_ids, attention_mask, token_type_ids, position_ids, inputs_embeds, labels, output_attentions, output_hidden_states, return_dict) 1071 r""" 1072 labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*): 1073 Labels for computing the sequence classification/regression loss. Indices should be in `[0, ..., 1074 config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If 1075 `config.num_labels > 1` a classification loss is computed (Cross-Entropy). 1076 """ 1077 return_dict = return_dict if return_dict is not None else self.config.use_return_dict -> 1079 outputs = self.deberta( 1080 input_ids, 1081 token_type_ids=token_type_ids, 1082 attention_mask=attention_mask, 1083 position_ids=position_ids, 1084 inputs_embeds=inputs_embeds, 1085 output_attentions=output_attentions, 1086 output_hidden_states=output_hidden_states, 1087 return_dict=return_dict, 1088 ) 1090 encoder_layer = outputs[0] 1091 pooled_output = self.pooler(encoder_layer) File ~/miniconda3/envs/fastai/lib/python3.10/site-packages/torch/nn/modules/module.py:1773, in Module._wrapped_call_impl(self, *args, **kwargs) 1771 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc] 1772 else: -> 1773 return self._call_impl(*args, **kwargs) File ~/miniconda3/envs/fastai/lib/python3.10/site-packages/torch/nn/modules/module.py:1784, in Module._call_impl(self, *args, **kwargs) 1779 # If we don't have any hooks, we want to skip the rest of the logic in 1780 # this function, and just call forward. 1781 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks 1782 or _global_backward_pre_hooks or _global_backward_hooks 1783 or _global_forward_hooks or _global_forward_pre_hooks): -> 1784 return forward_call(*args, **kwargs) 1786 result = None 1787 called_always_called_hooks = set() File ~/miniconda3/envs/fastai/lib/python3.10/site-packages/transformers/models/deberta_v2/modeling_deberta_v2.py:818, in DebertaV2Model.forward(self, input_ids, attention_mask, token_type_ids, position_ids, inputs_embeds, output_attentions, output_hidden_states, return_dict) 815 if not return_dict: 816 return (sequence_output,) + encoder_outputs[(1 if output_hidden_states else 2) :] --> 818 return BaseModelOutput( 819 last_hidden_state=sequence_output, 820 hidden_states=encoder_outputs.hidden_states if output_hidden_states else None, 821 attentions=encoder_outputs.attentions, 822 ) File <string>:6, in __init__(self, last_hidden_state, hidden_states, attentions) File ~/miniconda3/envs/fastai/lib/python3.10/site-packages/transformers/utils/generic.py:392, in ModelOutput.__post_init__(self) 389 first_field = getattr(self, class_fields[0].name) 390 other_fields_are_none = all(getattr(self, field.name) is None for field in class_fields[1:]) --> 392 if other_fields_are_none and not is_tensor(first_field): 393 if isinstance(first_field, dict): 394 iterator = first_field.items() File ~/miniconda3/envs/fastai/lib/python3.10/site-packages/transformers/utils/generic.py:139, in is_tensor(x) 134 """ 135 Tests if `x` is a `torch.Tensor`, `tf.Tensor`, `jaxlib.xla_extension.DeviceArray`, `np.ndarray` or `mlx.array` 136 in the order defined by `infer_framework_from_repr` 137 """ 138 # This gives us a smart order to test the frameworks with the corresponding tests. --> 139 framework_to_test_func = _get_frameworks_and_test_func(x) 140 for test_func in framework_to_test_func.values(): 141 if test_func(x): File ~/miniconda3/envs/fastai/lib/python3.10/site-packages/transformers/utils/generic.py:124, in _get_frameworks_and_test_func(x) 113 """ 114 Returns an (ordered since we are in Python 3.7+) dictionary framework to test function, which places the framework 115 we can guess from the repr first, then Numpy, then the others. 116 """ 117 framework_to_test = { 118 "pt": is_torch_tensor, 119 "tf": is_tf_tensor, (...) 122 "mlx": is_mlx_array, 123 } --> 124 preferred_framework = infer_framework_from_repr(x) 125 # We will test this one first, then numpy, then the others. 126 frameworks = [] if preferred_framework is None else [preferred_framework] File ~/miniconda3/envs/fastai/lib/python3.10/site-packages/transformers/utils/generic.py:99, in infer_framework_from_repr(x) 94 def infer_framework_from_repr(x): 95 """ 96 Tries to guess the framework of an object `x` from its repr (brittle but will help in `is_tensor` to try the 97 frameworks in a smart order, without the need to import the frameworks). 98 """ ---> 99 representation = str(type(x)) 100 if representation.startswith("<class 'torch."): 101 return "pt" KeyboardInterrupt:
Prediction and Submission
Loading test data, generating predictions, and creating a submission file in the required format.
eval_df = pd.read_csv(path/'test.csv')
eval_df| id | anchor | target | context | |
|---|---|---|---|---|
| 0 | 4112d61851461f60 | opc drum | inorganic photoconductor drum | G02 |
| 1 | 09e418c93a776564 | adjust gas flow | altering gas flow | F23 |
| 2 | 36baf228038e314b | lower trunnion | lower locating | B60 |
| 3 | 1f37ead645e7f0c8 | cap component | upper portion | D06 |
| 4 | 71a5b6ad068d531f | neural stimulation | artificial neural network | H04 |
| 5 | 474c874d0c07bd21 | dry corn | dry corn starch | C12 |
| 6 | 442c114ed5c4e3c9 | tunneling capacitor | capacitor housing | G11 |
| 7 | b8ae62ea5e1d8bdb | angular contact bearing | contact therapy radiation | B23 |
| 8 | faaddaf8fcba8a3f | produce liquid hydrocarbons | produce a treated stream | C10 |
| 9 | ae0262c02566d2ce | diesel fuel tank | diesel fuel tanks | F02 |
| 10 | a8808e31641e856d | chemical activity | dielectric characteristics | B01 |
| 11 | 16ae4b99d3601e60 | transmit to platform | direct receiving | H04 |
| 12 | 25c555ca3d5a2092 | oil tankers | oil carriers | B63 |
| 13 | 5203a36c501f1b7c | generate in layer | generate by layer | G02 |
| 14 | b9fdc772bb8fd61c | slip segment | slip portion | B22 |
| 15 | 7aa5908a77a7ec24 | el display | illumination | G02 |
| 16 | d19ef3979396d47e | overflow device | oil filler | E04 |
| 17 | fd83613b7843f5e1 | beam traveling direction | concrete beam | H05 |
| 18 | 2a619016908bfa45 | el display | electroluminescent | C23 |
| 19 | 733979d75f59770d | equipment unit | power detection | H02 |
| 20 | 6546846df17f9800 | halocarbyl | halogen addition reaction | C07 |
| 21 | 3ff0e7a35015be69 | perfluoroalkyl group | hydroxy | A63 |
| 22 | 12ca31f018a2e2b9 | speed control means | control loop | G05 |
| 23 | 03ba802ed4029e4d | arm design | steel plate | F16 |
| 24 | c404f8b378cbb008 | hybrid bearing | bearing system | F04 |
| 25 | 78243984c02a72e4 | end pins | end days | A44 |
| 26 | de51114bc0faec3e | organic starting | organic farming | B61 |
| 27 | 7e3aff857f056bf9 | make of slabs | making cake | E04 |
| 28 | 26c3c6dc6174b589 | seal teeth | teeth whitening | F01 |
| 29 | b892011ab2e2cabc | carry by platform | carry on platform | B60 |
| 30 | 8247ff562ca185cc | polls | pooling device | B21 |
| 31 | c057aecbba832387 | upper clamp arm | end visual | A61 |
| 32 | 9f2279ce667b21dc | clocked storage | clocked storage device | G01 |
| 33 | b9ea2b06a878df6f | coupling factor | turns impedance | G01 |
| 34 | 79795133c30ef097 | different conductivity | carrier polarity | H03 |
| 35 | 25522ee5411e63e9 | hybrid bearing | corrosion resistant | F16 |
eval_df['input'] = 'TEXT1: ' + eval_df.context + '; TEXT2: ' + eval_df.target + '; ANC1: ' + eval_df.anchoreval_ds = Dataset.from_pandas(eval_df)eval_ds = eval_ds.map(tok_func, batched=True)# Now predict using the properly formatted dataset
preds = trainer.predict(eval_ds).predictions.astype(float)preds = np.clip(preds, 0, 1)
predsarray([[0.48],
[0.82],
[0.34],
[0.35],
[0. ],
[0.43],
[0.36],
[0.05],
[0.09],
[1. ],
[0.17],
[0.28],
[0.67],
[0.7 ],
[0.79],
[0.34],
[0.22],
[0.03],
[0.48],
[0.25],
[0.34],
[0.21],
[0.08],
[0.16],
[0.52],
[0. ],
[0. ],
[0.03],
[0. ],
[0.68],
[0.28],
[0.04],
[0.71],
[0.35],
[0.35],
[0.15]])import datasets
submission = datasets.Dataset.from_dict({
'id': eval_df['id'],
'score': preds
})
submission.to_csv('submission.csv', index=False)862